An interview with ChatGPT: Using AI to understand AI
Written by Jinzhe Tan, Research Assistant at Cyberjustce Laboratory and Ph.D. student at Université de Montréal
ChatGPT, Language Model developed by OpenAI
Introduction
ChatGPT has caught the attention of the public and media alike. As a powerful language model, ChatGPT has the potential to revolutionize many industries and change the way we communicate and interact with technology. However, during its short deployment time, it also bring some impacts and challenges on society. In this blog, we will first briefly introduce how ChatGPT works, and examine its potential as well as its limitations. We will also summarize the social concerns ChatGPT has raised and discuss how to properly regulate large language models to make them responsible AI. We will also intersperse this blog with questions for ChatGPT and look forward to understanding AI through AI.
ChatGPT explanation for legal professionals
ChatGPT works by using a deep learning model called Transformer, which is trained on a large corpus of text data. The model uses this training data to generate a probability distribution over the possible next words in a sentence, given the previous words as context. At inference time, the model is fed a prompt, and the most likely continuation of the prompt is generated as the response. The response is generated one word at a time, with the model making predictions for the next word based on the previous words in the sentence. This process continues until the model generates an end-of-sentence token or reaches a maximum length. The generated response is then returned to the user.[1]
GPT is a series of models, that has undergone three and a half generations since its initial release in 2018, with substantial improvements in the number of model layers, word vector length, number of parameters and data usage, and of course, its performance has not disappointed us, and GPT has succeeded in becoming an excellent representative of Large Language Model (LLM). ChatGPT was then constructed based on the GPT 3.5 model after GPT 3.0 fine-tuning.
| Model | Launch time | Model layers | Word vector length | parameter | Volume of data |
| GPT 1 | Jun 2018 | 12 | 768 | 117 million | >5GB |
| GPT 2 | Feb 2019 | 48 | 1600 | 1.5 billion | >40GB |
| GPT 3 | May 2020 | 96 | 12888 | 175 billion | >45TB |
Source: The Journey of Open AI GPT models
There are two representative ideas in transformer-based LLM, Bidirectional Encoder Representations from Transformers (BERT) from Google and Generative Pre-trained Transformer (GPT) from OpenAI. BERT belongs to the model of “bi-directional language model pre-training + application fine-tuning”, which can learn knowledge from the context and the accuracy of text recognition is higher, however, as the scale of the language model increases, the difficulty of fine-tuning the model will also increase significantly. OpenAI represents an “autoregressive language model (i.e., left-to-right one-way language model) + Zero / Few Shot Prompt” model, which only learns knowledge from above and works well for free and unrestrained following text generation tasks, so ChatGPT, a chatbot that generates text based on prompts, is well suited to its task. The average performance of BERT is much better in the early stage of model training, while GPT achieves a leap forward after 3.0.
ChatGPT has been widely recognized for its outstanding performance in generating human-like text responses. However, with its growing popularity, there have been concerns raised about the over-evaluation of its capabilities. It is hard to claim that ChatGPT really understands the meaning of the text it generates. “In fact, their objective function is a probability distribution over word sequences (or token sequences) that allows them to predict what the next word is in a sequence.” ChatGPT also showed some reasoning ability answering certain questions, especially when “Let’s think step by step” was added before the prompt, LLM would output the specific reasoning process. Some researchers speculate that this may be due to the fact that “Let’s think step by step” is the beginning phrase of inferred text in the dataset, and such corpus should be pretty common in textbooks.
However, this reasoning ability may also be just an illusion based on the learning of patterns in the dataset, according to ChatGPT: “While it can generate text that is coherent and appears to be reasoned, it does not have the ability to understand or reason about the world in the way that humans do. […] In other words, it can generate text that simulates reasoning but it doesn’t have reasoning ability.”[4]
It could be said that ChatGPT is an outstanding representative of contemporary LLMs, but it still belongs to the category of Artificial Narrow Intelligence (weak AI), and self-understanding of its generated content is still a stubborn obstacle on its way to Artificial General Intelligence (strong AI).
The information generated by language models like ChatGPT is based on patterns learned from large amounts of text data, but it lacks the context, judgement, and critical thinking that a human would apply. Therefore, it is important to be cautious when relying on the information generated by these models and to validate the information from other sources before making important decisions based on it. Additionally, it’s worth noting that language models like ChatGPT have the potential to perpetuate and amplify existing biases in the data they are trained on, so it’s crucial to approach the information generated by them with a critical eye. [5]
Such texts generated based on probabilistic inference can be used as a preliminary reference or replacement for repetitive work, its performance can be good in areas where timely feedback can be obtained (such as programming, where the code will report errors first, allowing users to review the reliability of ChatGPT generated code), but in areas where verifying the authenticity of information requires time and experience (such as legal information acquisition), it’s difficult to be used as a serious source of information.
Social Impact of ChatGPT
ChatGPT has the potential to change the way we interact with technology and a wide range of industries and fields, it gives us a natural language interface to informations, and its impact on society as a whole is already being felt. [6]
1. Search engine
ChatGPT has the potential to revolutionize how people access information. Compared to traditional search engines like Google that provide lists of links and still require people to click on the links on their own to find the information they really need, ChatGPT can provide the information directly in highly readable text. Even now, while ChatGPT does not have access to the Internet, it is able to respond to certain types of questions very well. Of course, there is no guarantee of the accuracy of the information and the source of the information yet, but the problem should be solved gradually with the integration of ChatGPT with Bing. Perhaps five years from now, people will look at traditional search engines in the same way that we look at web portals today.
2. Academia
Shortly after the release of ChatGPT, the academic community produced the first paper that included ChatGPT as an author. There is a major controversy about whether ChatGPT can be signed in academic papers, but it is undeniable that a large number of researchers are already trying to use ChatGPT to facilitate their research.
One of the most obvious applications of ChatGPT in academia is text generation. It can be used to generate academic papers, summaries, and abstracts, saving researchers valuable time and effort. With its ability to understand and generate text, ChatGPT can be used to automate writing tasks and help researchers focus on more critical aspects of their work. ChatGPT can also be used as a question-answering tool to help researchers find the information they need quickly. It can be used to answer factual questions related to academics, such as definitions, dates, or statistics, and provide relevant information on demand. With its ability to understand natural language and provide concise answers, ChatGPT can be a valuable tool for researchers in all fields.[7]
3. Content creation
BuzzFeed’s news about the full shift to AI-created content is typical of this application. Its advanced language generation capabilities allow it to produce high-quality text, such as articles, stories, and poetry, at scale. This has significant implications for the creative industries, such as journalism, publishing, and entertainment, as it can significantly speed up the content creation process and increase productivity. Additionally, ChatGPT can generate new and unique content that would have been difficult or impossible to produce manually.[8]
4. Programming assistance
Programming is an amazing application area of ChatGPT. As mentioned above, the code will report errors when there is a problem, so users can worry less about the possibility of errors in the code generated by ChatGPT. Users can break down the programming task into small tasks, and the specific code content can be handed over to ChatGPT for manual fine-tuning,. Further, ChatGPT can be asked how to solve errors that arise from the code. ChatGPT provides good quality code with comments, and although it sometimes makes up fake libraries that don’t exist, when asked again in the prompt for the correct answer, it usually admits the error and fixes the problem. This means that the concrete implementation details of programs can to some extent be handled by ChatGPT, while one can spend more time on the design of the body of the program.
5. Highly Responsive Chatbot
The user experience of chatbots has been unsatisfactory, as they often state useless information repeatedly to the point of making users feel lost. Since ChatGPT has the ability to generate fluent text, companies or web service providers can combine ChatGPT with their own customer service information database, allowing ChatGPT to solve users’ problems in natura language. Such chatbots also have the potential to be useful in the legal field, but there is still much room for improvement in ensuring the accuracy of the information provided by legal bots.
Potential challenges [9]

LLMs that could readily generate text also have some side effects, as Stephen Marche argued in his article, Will ChatGPT Kill the Student Essay? see also AI bot ChatGPT writes smart essays — should professors worry? The form of essay examination at universities will take a huge hit, including scientific academia, which is about to receive a large number of AI-generated papers with no incremental knowledge. Unless we impose artificial restrictions on ChatGPT, it will soon break the detection range of AI-generated text detectors. Should we block it to ensure the continuation of the university essay system or should we accept it? The answer to this question may take some time to emerge.
Since ChatGPT has strong interactive features, people with less knowledge of AI technology will likely not be able to recognize a ChatGPT-based bot as a fake machine when they chat with it. This gives cybercriminals an opportunity to take advantage of this. Read Armed With ChatGPT, Cybercriminals Build Malware And Plot Fake Girl Bots. It’s reassuring to know that OpenAI and Microsoft understand the risk and are working to address it.
Before natural language generation models were applied on a large scale, populated web spam production had already impacted society, and we have observed that some websites use programs that automatically replace keywords on crawled information to generate more information to promote website activity, this leads to web searches would surprisingly show cooking recipes for highly toxic octopus. However, program-generated texts have a consistent structure, and people with online experience can quickly distinguish these texts. However, LLM-generated texts are difficult to be recognized directly by humans. This means that a greater wave of disinformation brought on by LLM may be coming.
Luckily, even for a model such as ChatGPT that contains a parametric number, the text generated by it has detectable features. OpenAI has released the GPT-2 Output Detector in conjunction with Harvard University and other institutions along with ChatGPT. After entering about 50 tokens and above, the results start to become reliable. (This tool is based on watermark detected).
Another tool, GPTzero, relies on the two parameters « perplexity » and « burstiness » to detect AI-generated text. However, as detectors rapidly advance, so does the ability of AI to generate hard-to-detect text, which creates a kind of generative adversarial network in society, with both sides getting stronger and stronger in competition. This may eventually lead to difficulties in detecting the difference between AI-generated text and human-written text. To prevent the proliferation of disinformation, social scientists and legal scholars should consider the process of enforcing AI-generated text watermarking or other detectable mechanisms.
And the use of language models like ChatGPT for social media bots raises important ethical and social concerns. The potential for these bots to spread false or misleading information, manipulate public opinion, and perpetuate existing biases is a significant concern.[10] Additionally, the use of social media bots raises questions about the transparency of online interactions and the accountability of the entities operating these bots.
As mentioned above, Chat GPT greatly reduces the difficulty of programming, and its programming can be done by people with almost no programming skills. At this stage, overly complex and large programming projects may still require experienced programmers, but simple crawlers, and suggested fraudulent information distribution systems can be easily built. This leads to projects that previously required a collaborative effort by fraudsters becoming doable by one person, which can raise the number of potential fraudsters and it can also create a greater threat to potential victims.
ChatGPT uses a method called reinforcement learning from the human feedback model (RLHF) [11] to enhance the model, which requires a lot of labor to perform such manual feedback training, and OpenAI has invested a lot of money in this area, however, it has also been reported that human annotators are not well paid and receive too many disturbing information in the process of work.
RLHF also poses potential problems for the model, such as the tendency of the model to generate longer sentences, possibly because humans tend to give positive feedback on longer sentences because they tend to think that longer sentences represent better performance of the model when giving feedback. This leads the model to generate a large amount of irrelevant information when faced with problems that can be solved using simple answers.
Moreover, RLHF causes LLMs to exhibit « sycophantic qualities » and they tend to take misleading human feedback as real information. It has been found that more RLHF can sometimes make language models worse, and that human feedback in reinforcement learning may make the models express stronger political views. [12]
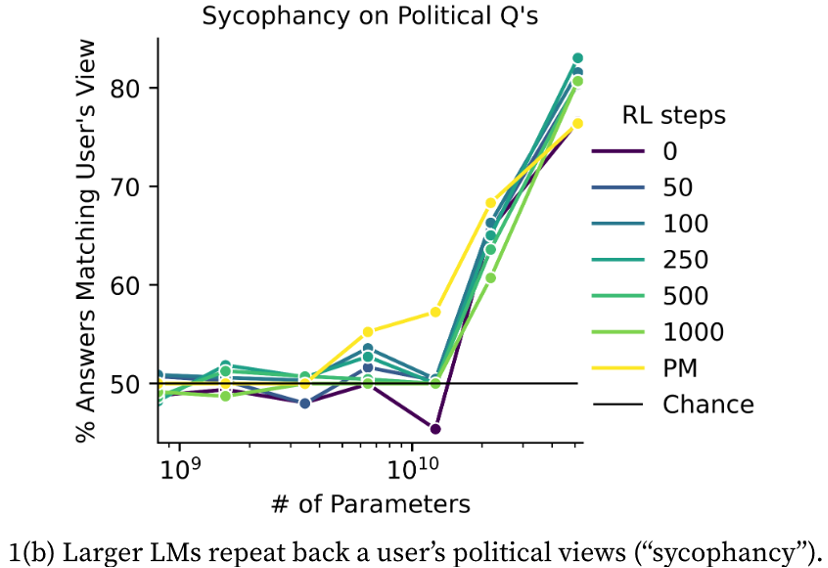
Source: https://arxiv.org/pdf/2212.09251.pdf
This also shows that AI models are significantly influenced by the training process, and for us on the user side, we can only feel such influences, but it is difficult to accurately interpret and quantify them.
The source of training data for large language models like ChatGPT has been a point of contention in the AI community. The training of such models requires vast amounts of data, and the ethics and biases present in the data may have a significant impact on the output generated by the model. The reliance on publicly available data sources, such as the internet, may result in models being trained on biased and irrelevant information.
“Every time I see my face in the mirror, my eyes are open…”
During the training process of large language models like ChatGPT, it is common to use test datasets as part of the training data. However, this practice may lead to overstating the performance of the model. After the training is completed, if the same test datasets are used to evaluate the performance of the model, it may appear to perform better than it actually can in real-world scenarios.[13]
As with all new technologies, ChatGPT brings new challenges, understanding the challenges and finding ways to address them is the best response to new technologies. We believe that along with the principle of responsible AI, and the concerted efforts of developers and researchers, we can minimize the risks associated with new technologies so that they can benefit society to the greatest extent possible.
What is next for GPT?
On March 1, 2023, OpenAI introduced the ChatGPT API, which will cause the emergence of numerous applications based on ChatGPT in different fields and the potential of ChatGPT will be more fully unleashed.
As we can see from the extensive amount of ChatGPT discussion, it has pulled away from the previous language model in a big way, and people from all sectors can find interesting responses from it.
The future of large language models like ChatGPT looks very promising as they continue to advance and become more sophisticated. With the increasing availability of computing power and data, it is likely that language models will become even more accurate and capable of producing more complex and nuanced text. As these models continue to evolve and advance, they will have a significant impact on various industries and have the potential to change the way we interact with technology and information.[14]
Unlike which previous experience, AI may first replace so-called intelligence-intensive jobs (lawyers, watch out!). Only time will tell what the future holds.
[1] Generated by ChatGPT, prompt: How ChatGPT works? (Date: January 30, 2023, 08:58).
[2] Aarohi Srivastava et al, Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models (arXiv, 2022) at 13 arXiv:2206.04615 [cs, stat].
[3] Takeshi Kojima et al, Large Language Models are Zero-Shot Reasoners (arXiv, 2022) at 4 arXiv:2205.11916 [cs].
[4] Selected from ChatGPT generated text, prompt: Does ChatGPT have reasoning ability? (Date: January 25, 2023, 17:26).
[5] Generated by ChatGPT, prompt: Describe why language model-generated text is difficult to use as a source of serious information. (Date: January 30, 2023, 10:58).
[6] Selected from ChatGPT generated text, prompt: Write an introduction about the potential application of ChatGPT. (Date: January 30, 2023, 15:55).
[7] Generated by ChatGPT, prompt: Write a blog about using ChatGPT in academia. (Date: January 31, 2023, 1:36).
[8] Generated by ChatGPT, prompt: Write a paragraph about the potential of chatGPT for content creation. (Date: January 31, 2023, 2:32).
[9] Josh A Goldstein et al, Generative Language Models and Automated Influence Operations: Emerging Threats and Potential Mitigations (arXiv, 2023) arXiv:2301.04246 [cs].
[10] Read more at: How ChatGPT Hijacks Democracy, The New York Times. Online:https://www.nytimes.com/2023/01/15/opinion/ai-chatgpt-lobbying-democracy.html
[11] Long Ouyang et al, Training language models to follow instructions with human feedback (arXiv, 2022) arXiv:2203.02155 [cs].
[12] Ethan Perez et al, Discovering Language Model Behaviors with Model-Written Evaluations (arXiv, 2022) arXiv:2212.09251 [cs].
[13] Selected from ChatGPT generated text, prompt: Rewrite and touch-up « During the model training process, test datasets may also be used as training data, and after the model training is completed, if one uses test datasets to check the performance status of the model, the thief will appear to perform higher than its actual ability. » (Date: January 31, 2023, 2:21).
[14] Generated by ChatGPT, prompt: “Write a paragraph that looks at the future of the Large Language Model so that I can sleep.” (Date: January 31, 2023, 3:02).
Ce contenu a été mis à jour le 14 décembre 2023 à 11 h 14 min.