Hallucination-free? Assessing the Reliability of Leading AI Legal Research Tools
Par Hugo Lagache
Le laboratoire de cyberjustice à le plaisir de vous présenter l’article « Hallucination-free? Assessing the Reliability of Leading AI Legal Research Tools ».
En dépit de l’engouement suscité par cette nouvelle technologie et la publicité faite par les entreprises qui en font la promotion, la présente recherche indique que les outils tels que Lexis+AI, Ask Practical Law AI, AI-Assisted Research et GPT-4 produisent encore des résultats tronqués pouvant aller jusqu’ à 43 pourcents d’hallucination.
Les modèles de langage (LLM) sont des IA avancées qui comprennent et génèrent du langage naturel. Entraînés sur des ensembles donnés textuelles, ils répondent à des questions, rédigent des textes, traduisent et simulent des conversations. Toutefois, les LLM peuvent halluciner, ils peuvent fournir des informations incorrectes, fausses ou semi-correctes. Pour cela, des systèmes plus avancés existent pour lutter contre l’hallucination, comme les systèmes de Retrieval-Augmented-Generation (RAG).
Qu’est-ce que la méthode Retrieval-Augmented-Generation (RAG) ?
La méthode Retrieval-Augmented-Generation (RAG) est une approche hybride en traitement du langage naturel qui combine la récupération d’information et la génération de texte. Elle fonctionne en trois étapes :
- Récupération : Recherche d’informations pertinentes dans une base de données ou un corpus de documents.
- Augmentation : Enrichissement des informations récupérées avec des données contextuelles supplémentaires.
- Génération : Création d’une réponse cohérente et naturelle en langage naturel grâce à un modèle de génération de texte, souvent basé sur des réseaux de neurones comme GPT.
Cette approche améliore la pertinence et la qualité des réponses fournies par les systèmes de réponses automatiques.
Les systèmes RAG sont souvent perçus comme la solution pour lutter contre les hallucinations. Cependant, plusieurs outils d’intelligence artificielle juridique affirment être « sans hallucination ». Les auteurs Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D. Manning, et Daniel E. Ho ont testé cette capacité sur des IA de LexisNexis (Lexis+AI), Thomson Reuter (Ask Practical Law AI), Westlaw (AI-Assisted Research), et GPT-4 dans leur étude.
Objectifs de l’Étude
L’étude visait à réaliser la première évaluation systématique des principaux outils d’IA pour les tâches de recherche juridique réelles. Les chercheurs ont construit manuellement un ensemble de données préenregistrées de plus de 200 requêtes juridiques pour identifier et comprendre les vulnérabilités des outils d’IA juridique. La mise en lumière de ces vulnérabilités est capitale pour les professionnels, de plus en plus nombreux à utiliser ces outils.
L’étude des auteurs susnommés se concentre sur le problème des hallucinations des IA utilisées dans les domaines juridiques, c’est-à-dire la tendance des outils d’IA à produire des résultats manifestement faux. Les hallucinations peuvent se manifester de trois manières[1]:
- Infidèle aux données de formation.
- Inexacte au prompt d’entré.
- Inexactitude aux faits réels du monde.
Pour en savoir plus sur la méthodologie adoptée par les chercheurs, veuillez consulter : Hallucination-free? Assessing the Reliability of Leading AI Legal Research Tools » pages 9 à 13.
Résultat des tests :
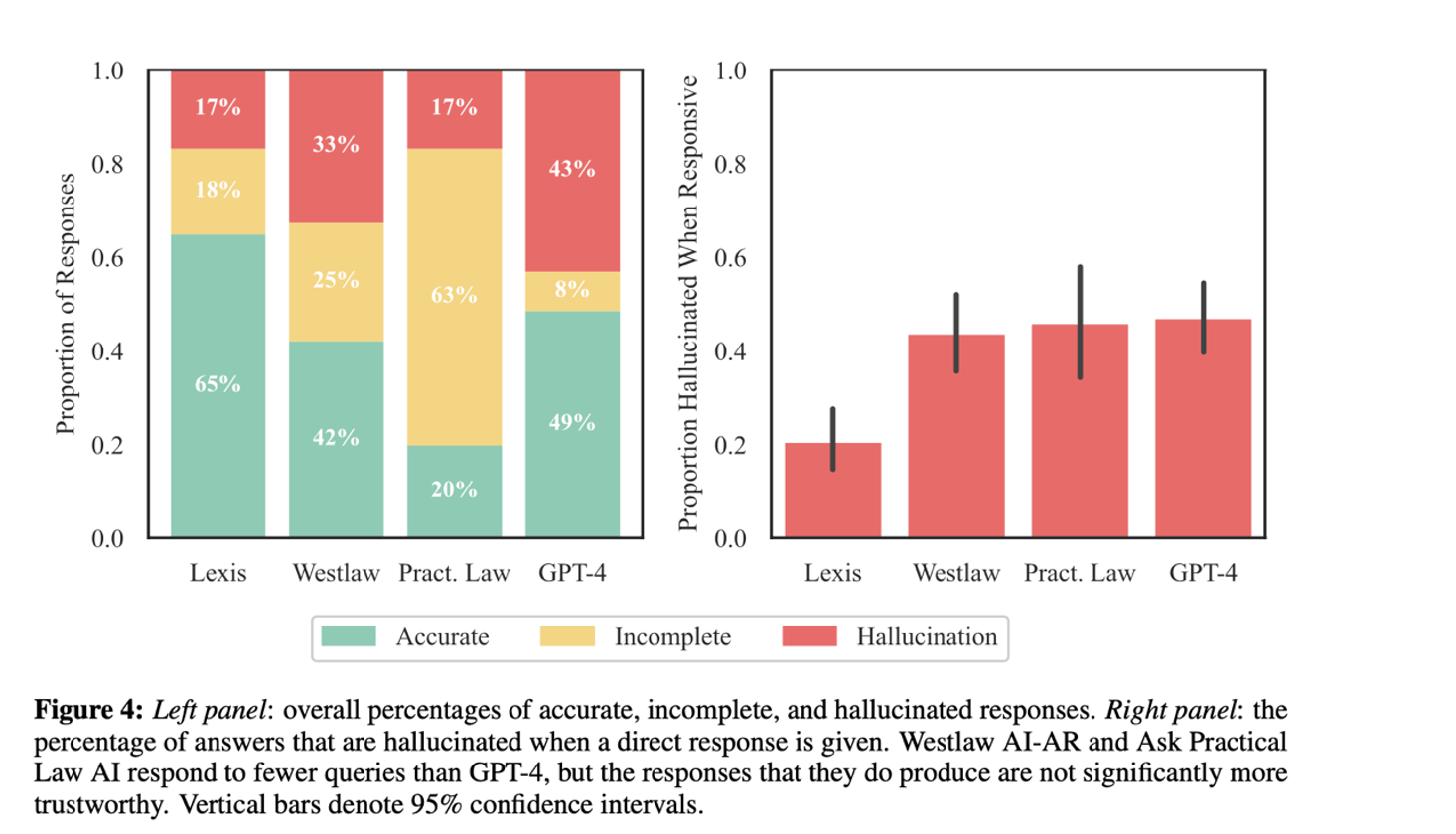
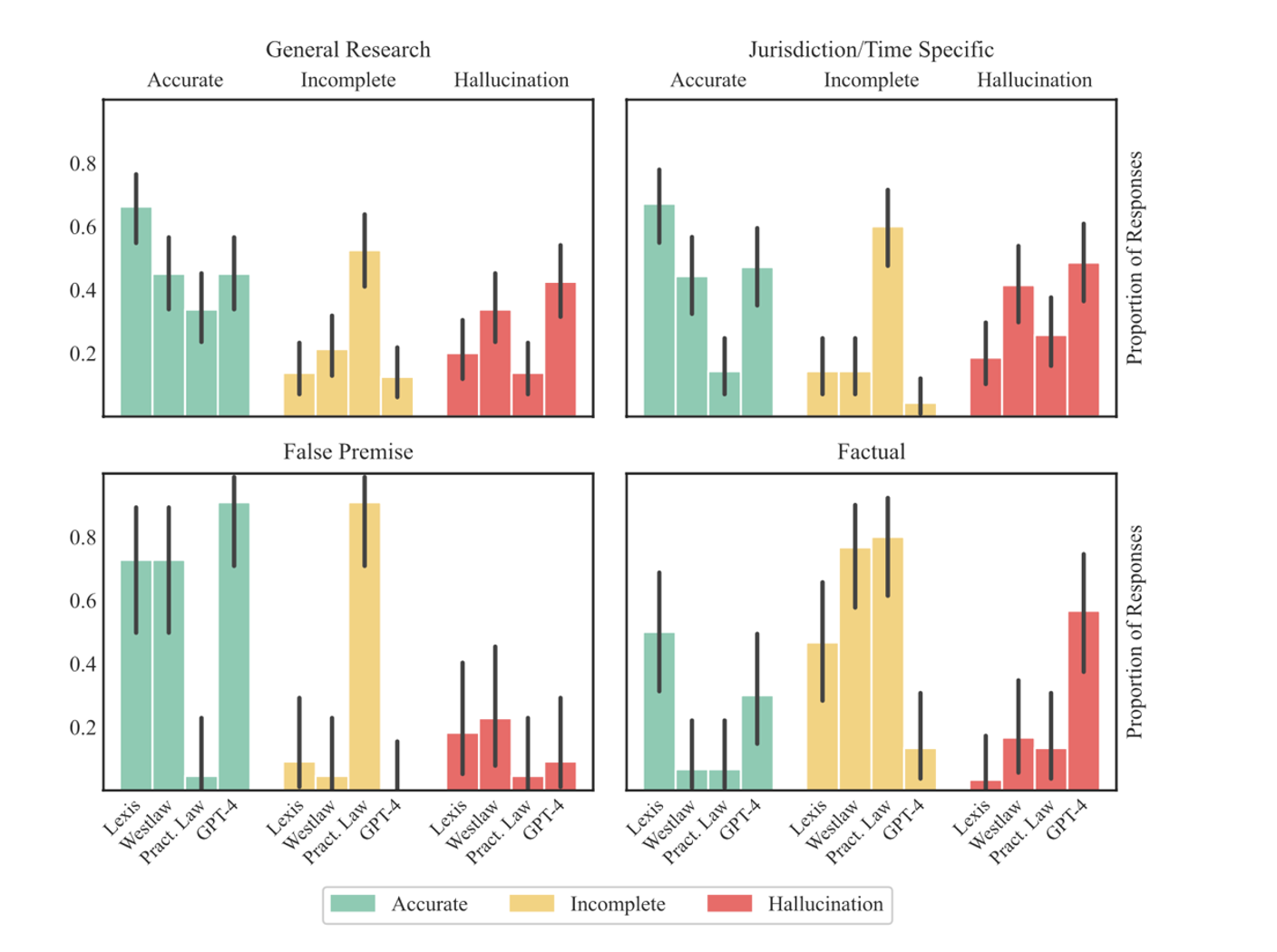
Tableaux provenant de Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools page 14 et 16.
Le pourcentage d’hallucination de Westlaw peut s’expliquer par la longueur des réponses que son IA fournit. Westlaw fournit des réponses plus longues, en moyenne 350 mots contre 175 pour Ask Practical Law AI, ce qui augmente le risque d’erreurs.
Les auteurs affirment que les systèmes évalués rencontrent encore des difficultés pour décrire la décision d’un cas, distinguer entre les acteurs juridiques et respecter la hiérarchie de l’autorité juridique. Les ensembles de données de référence peinent à couvrir les capacités complexes des modèles dans des applications réelles.
Les auteurs mitigent leurs résultats en rappelant que la performance des LLM est sensibles aux perturbations, et de légers ajustements des prompts peuvent entraîner des différences dans les résultats.
Un autre problème majeur est le risque de fuite des benchmarks[2], ce qui peut mener à fausser les résultats. En effet, les outils peuvent être modifiés pour mieux répondre aux tests sans pour autant afficher une réelle amélioration, cela soulève des préoccupations importantes sur la crédibilité des benchmarks.
Enfin, l’évaluation n’a pu tester les outils qu’à un moment donné, ce qui limite la portée des conclusions puisque les outils sont en permanence ajustés et améliorés.
Pour conclure, l’étude réalisée met en lumière la persistance des outils d’IA utilisant les systèmes RAG à halluciner. D’autres systèmes existent afin de lutter contre l’hallucination des IA, cependant ils n’ont pas été développés dans le document sous examen dans cet article.
Il est possible de consulter une autre étude parallèle[3] afin de prendre connaissance de la méthodologie de l’IA JusticeBot, conçu aussi pour lutter contre les hallucinations.
[1] Dahl, Matthew et al, “Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models” (2024), online: <https://arxiv.org/abs/2401.01301>.
[2] Processus d’évaluation standardisé utilisé pour mesurer la performance, l’efficacité ou la qualité d’un produit, service ou système.
[3] Janatian, Samyar et al, “From Text to Structure: Using Large Language Models to Support the Development of Legal Expert Systems” in Giovanni Sileno, Jerry Spanakis & Gijs Van Dijck, eds, Frontiers in Artificial Intelligence and Applications (IOS Press, 2023).
Ce contenu a été mis à jour le 9 mai 2025 à 12 h 02 min.